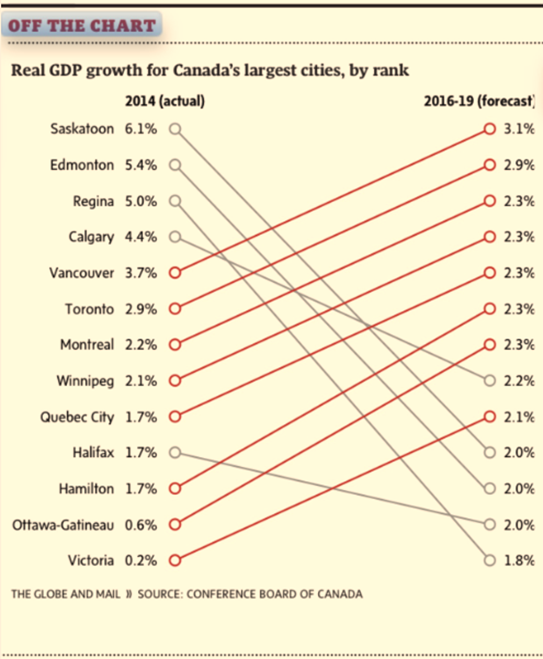
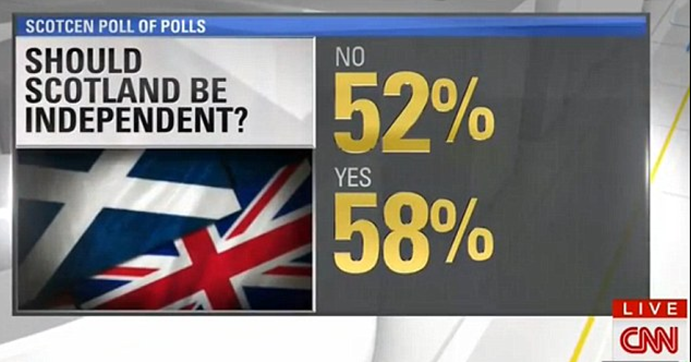
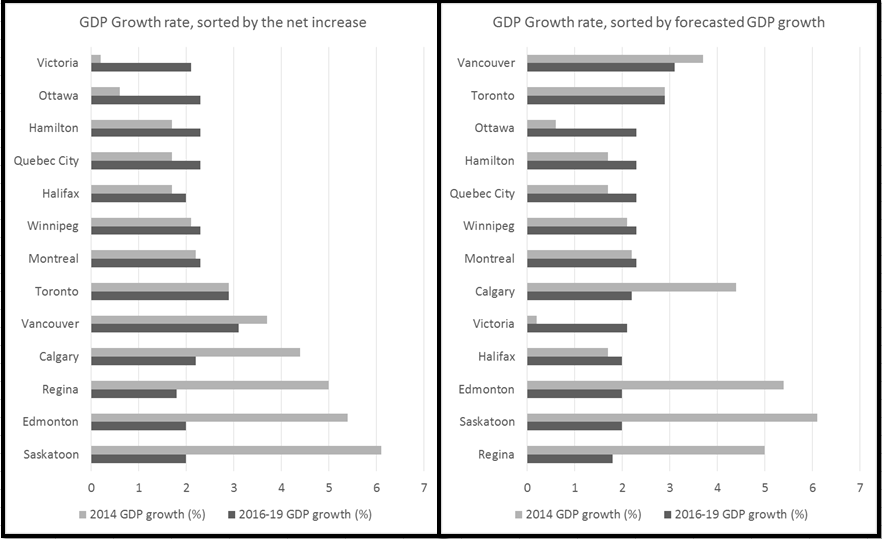
Some say
data is the new oil. Others equate its worth to water. And then there are those
who believe that data scientists will be (in fact, they already are) one of the
most sought-after workers in knowledge economies.
Millions
of data-centric jobs require millions of trained data scientists. However, the
installed capacity of graduate and undergraduate programs in data science is
nowhere near meeting this demand over the next many years.
So how
do we produce data scientists?
Given
the enormous demand for data scientists and the fixed supply from higher
education institutions, it is quite likely that one must look beyond colleges
and universities to train a large number of data scientists desired by the
marketplace.

Getting
trained on the job is one possible route. This will require repurposing the existing
workforce. To prepare the current workforce for data science, one needs training
manuals. One such manual is Modern Data Science with R (MDSR).
Published
by the CRC Press (Taylor and Francis Group) and authored by three leading
academics: Professors Baumer, Kaplan, and Horton, MDSR is the missing manual
for data science with R. The book is equally relevant to data science programs
in higher ed as it is to practitioners who would like to embark on a career in
data science or to get a taste of an aspect of data science that they have not
explored in the past.
As the
book’s name suggests, the text is based on R, one of the most popular and versatile
computing platforms. R is a freeware
and is being developed by thousands of volunteers in real time. In addition to base
R, which comes bundled with thousands of commands and functions, the user-written
packages, whose number has exceeded 14,000 (as of May 2019), further expand the
universe of features making R perhaps the most diverse computing platform.
Despite the
immense popularity of data science, only a handful of titles focus exclusively
on the topic. Hadley Wickham’s R for Data Science and R Cookbook by
Paul Teetor are the other two other worthy texts. MDSR is unique in the sense
that it serves as an introduction to a whole host of analytic techniques that are
seldom covered in one title.
In the
following paragraphs, I’ll discuss the salient features of the textbook. I begin
with my favourite attribute of the book that deals with its organization. Instead
of muddling with theories and philosophies, the book gets straight to business and
starts the conversation with data visualization. A graphic is worth a thousand
words, and MDSR is proof of it.
And
since Hadley Wickham’s
influence on data science is ubiquitous, MDSR also embraces Wickham’s implementation
of Grammar
of Graphics in R with one of the most popular R packages, ggplot2.
Another
avenue where Wickham’s influence is widely felt is data wrangling. A suite of R
packages bundled under the broader rubric of Tidyverse is influencing how data
scientists manipulate small and big data. Chapter 4 in MDSR perhaps is one of
the best and succinct introduction to data wrangling with R and Tidyverse. From
the simplest to more advanced examples, MDSR equips the beginner with the
basics and the advanced user with new ways to think about analyzing data.
A key feature
of MDSR is that it’s not another book on statistics or econometrics with R.
Yours truly is guilty of authoring one such book. Instead, MDSR is a book
focused squarely on data manipulation. The treatment of statistical topics is
not absent from the book; however, it’s not the book’s focus. It is for this
reason that the discussion on Regression models is in the appendices.
But make
no mistake, even when statistics is not the focus, MDSR offers sound advice on the
practice of statistics. Section 7.7, The perils of p-values, warns the novice statisticians
about not becoming the unsuspecting victims of hypothesis testing.
The
books distinguishing feature remains the diversity of data science challenges
it addresses. For instance, in addition to data visualization, the book offers
an introduction to interactive data graphics and dynamic data visualization.
At the
same time, the book covers other diverse topics, such as database management
with SQL, working with spatial data, analyzing text-based (non-structured)
data, and the analysis of networks. A discussion about ethics in data science
is undoubtedly a welcome feature in the book.
The book
is punctuated with hundreds of useful and hands-on data science examples and exercise,
providing ample opportunities to put concepts to practise. The book’s accompanying website offers additional
resources and code examples. At the time of this review, not all code was
available for download.
Also,
while I was able to reproduce more straightforward examples, I ran into trouble
with complex ones. For instance, I could not generate advanced spatial maps showing
flights origins and destinations.
My
recommendation to authors will be to maintain an active supporting website
because R packages are known to evolve, and some functionality may change or
disappear over time. For instance, the mapping algorithms that are part of the ggmap
package now require a Google maps API or else the maps will not display. This change
has likely occurred after the book was published.
In summary,
for aspiring and experienced data scientists, Modern Data Science with R is a book deserving to be in their
personal libraries.
Murtaza
Haider lives in Toronto and teaches in the Department of Real Estate
Management at Ryerson University. He is the author of Getting
Started with Data Science: Making Sense of Data with Analytics, which
was published by the IBM Press/Pearson.